Google Research: Reasoning Helps AI Recall What It Already Knows
Google Research shows that chain-of-thought is not only useful for hard reasoning. It can also help language models retrieve facts already stored in their weights through extra computation and factual priming.
Google Research published a useful study on a question that matters for anyone building with large language models: why does reasoning sometimes help a model answer simple factual questions?
The surprising finding is that chain-of-thought is not only a tool for complex math, coding, or multi-step planning. It can also help a model retrieve facts that are already stored inside its parameters. In other words, reasoning can act like a better access layer for the model's own memory.
Google's post describes two mechanisms behind this effect: a computational buffer effect and factual priming. Both are important for founders, operators, and product teams who want more reliable AI systems.
The core idea
A simple factual question does not appear to need reasoning. If the model knows the answer, it should answer. If it does not, it should not.
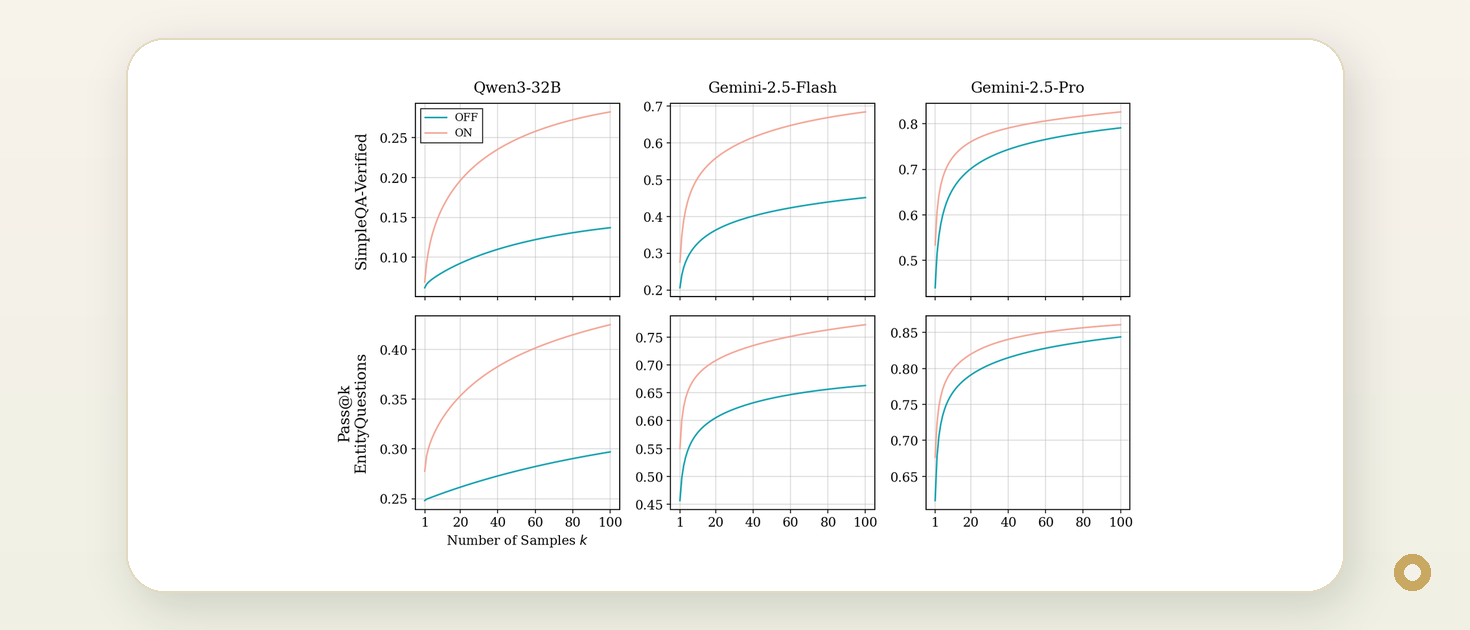
But Google Research found that this is not always how LLMs behave. When reasoning is enabled, models can recover correct answers that are difficult or nearly impossible to surface when reasoning is disabled. This was tested on closed-book question-answering benchmarks including SimpleQA Verified and EntityQuestions, across models such as Gemini 2.5 Flash, Gemini 2.5 Pro, and Qwen3-32B.
The practical takeaway: a model's knowledge is not the same as its ability to retrieve that knowledge on demand.
Mechanism 1: the computational buffer effect
The first mechanism is extra computation.
When a model generates reasoning tokens, it gets more forward passes before committing to a final answer. Google tested this by replacing the model's natural reasoning trace with repeated dummy text such as Let me think. Even though the dummy text carried no useful factual content, performance still improved compared with reasoning being turned off.
That suggests the extra token budget itself gives the model more runway to settle into a better answer.
This does not mean meaningless thinking is enough. The gains from dummy reasoning were limited and did not fully match natural reasoning. But it shows that part of the benefit comes from giving the model more computation time before the final response.
Mechanism 2: factual priming
The second mechanism is more interesting for real products.
Instead of performing a logical proof, the model often recalls nearby facts first. Those related facts prime the model toward the correct answer. Google calls this factual priming.
A simple example: if asked for the 10th King of Nepal, a reasoning model may first list earlier kings. That related context acts as a bridge to the answer. The model is not solving a math problem; it is warming up the relevant region of memory.
This explains why a short, structured pre-answer step can improve factual accuracy. The model is using its generated context as a self-retrieval mechanism.
The risk: bad intermediate facts can poison the answer
There is a catch. If the model generates incorrect intermediate facts, those hallucinations reduce the chance of getting the final answer right.
This is the operational lesson: reasoning traces are useful, but they should not be trusted blindly. A confident chain-of-thought with one bad premise can lead the model away from the truth.
For business systems, this points to a better pattern:
- let the model generate candidate reasoning or supporting facts,
- verify the factual steps where possible,
- prefer answers whose intermediate facts are supported,
- fall back to retrieval or human review when confidence is low.
This is especially relevant for AI agents handling sales, finance, legal, healthcare, research, or customer operations. In these workflows, being fluent is not enough. The system needs grounded intermediate steps.
What this means for AI product builders
The study supports a practical design principle: do not treat an LLM as a perfect database.
Even when a fact exists inside the model's weights, the model may not retrieve it reliably from a cold prompt. Reasoning, related facts, and verified context can all improve recall. But external retrieval, memory systems, and validation still matter.
For production AI systems, the winning architecture is usually not:
Ask the model and trust the answer.
A better architecture is:
Give the model room to reason, provide relevant context, verify key facts, and only then let it answer or act.
That is the difference between a demo chatbot and a reliable operating system for work.
Pratap AI view
This research reinforces something we see repeatedly in applied AI: reliability comes from system design, not just model selection.
A stronger model helps, but the surrounding workflow matters just as much. Retrieval, memory, verification, structured prompts, approval gates, and audit trails all shape whether an AI system can be trusted in daily operations.
Reasoning is valuable not because it makes the model magically intelligent, but because it gives the system more opportunities to retrieve, check, and correct itself before acting.
For founders and teams adopting AI, the lesson is simple: design your AI workflows so the model does not have to be perfect in one shot. Give it context, let it surface supporting facts, verify the fragile parts, and then use the answer.
That is how AI moves from clever output to dependable execution.
Source: Google Research - Thinking to recall: How reasoning unlocks parametric knowledge in LLMs
